Context engineering
LLM:er fungerar allra bäst när de får agera som ett gränssnitt där språket är det drivande sättet att interagera. Den verkliga intelligensen i LLM-drivna applikationer ligger dock inte främst i själva modellen, utan snarare i den kontext vi ger den.
På senare tid har begreppet context engineering dykt upp, som en vidareutveckling av prompt engineering. Vi har nämligen insett att enbart fokus på prompten har sina begränsningar och allt arbete omkring det är ibland överskattat. Du kan ha världens bäst formulerad prompt, men om LLM:en inte har rätt kontext kommer den ändå att underprestera.
Istället handlar det om att intelligent orkestrera kontexten för att nå bästa resultat. Context engineering är därför, även om det kan vara ett nytt buzzword, ett bättre begrepp än prompt engineering. Det fångar nämligen det faktum att kontext är allt, medan prompten bara är en liten pusselbit.
Hur relaterar detta till prompt engineering? Genom promptar beskriver vi för LLM:en hur den ska använda kontext för att svara användaren. Vi anger roll, regler och avgränsningar för hur den ska generera svar.
I mer komplexa system används promptar för att genomföra olika steg innan ett svar genereras. Promptar fungerar då som en konfiguration för systemet, men är också beroende av korrekt inhämtad kontext för att fungera. I vissa fall är LLM:en själv ansvarig för att avgöra vilken kontext som ska hämtas.
LLM:er kan förstå nyanser i språket och generera ny, väldigt mänsklig text. Men vi har alltid vetat om att språket modellerna producerar ofta är språkligt korrekt, men inte alltid faktamässigt korrekt.
På mina utbildningar brukar jag säga att AI inte vet vad den inte vet, eftersom den faktiskt inte vet någonting alls. Den är inte medveten. Människor läser dock in väldigt mycket intelligens i sättet språkmodeller uttrycker sig. Detta är inte konstigt, då språkmodeller härmar oss. Eftersom vi är intelligenta varelser och modellerna talar precis som vi, kan de framstå som lika intelligenta (och ibland även mer).
Den grundläggande utmaningen när vi bygger applikationer som uppfattas som intelligenta, är att vi förväntar oss att de alltid ska ge korrekta svar. När vi tidigare utvecklade NLU-drivna applikationer (Natural Language Understanding), matade vi ofta in svaren manuellt och säkerställde att de var korrekta. Svaren blev därför alltid rätt. Utmaningen låg istället i att matcha rätt fråga med rätt svar, vilket var svårare än vad man kunde tro.
Ärligt talat är situationen inte så annorlunda i LLM-drivna applikationer idag. Det kan kännas magiskt, men bakom varje välbyggt AI-system finns ett maskineri som säkerställer att rätt information hämtas, så att LLM:en kan ge de briljanta svar vi ibland ser. Förr behövde vi matcha fråga med rätt svar, och idag behöver vi matcha fråga med rätt kontext.
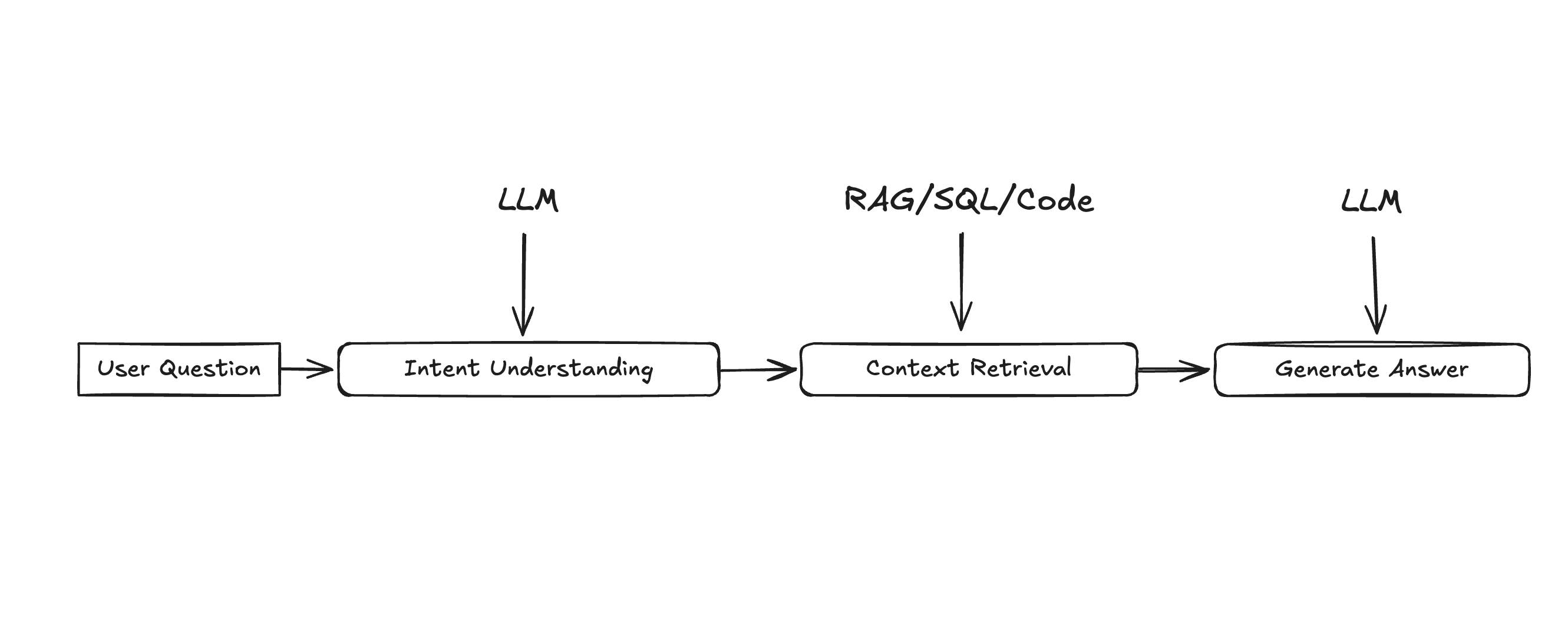
LLM-drivna applikationer ger sällan svar baserat endast på intränad kunskap. Istället promptas de att använda kontextuell information för att formulera sina svar. Oftast hämtat från en databas med kurerat innehåll.
Semantisk matchning och nyckelordsbaserad retrieval var våra första steg mot mer intelligenta system. Men dessa metoder fokuserade på att hitta relevant information, snarare än att presentera den språkligt och kontextuellt i en konversation.
Med de nya generationerna av LLM:er kunde vi kombinera informationshämtning med en imponerande förmåga att förstå och generera text baserad på djupare kontext. Det var i denna kombination av två kraftfulla teknologier – förbättrad retrieval och avancerad språkförståelse/generering – som RAG i sin nuvarande form verkligen kunde möjliggöra mer nyanserade och kontextuellt medvetna svar.
Men detta betyder inte att alla utmaningar är avklarade, eller att vi nu har perfekta system som alltid levererar korrekta svar. Verkligheten presenterar nya svårigheter. Vi måste hantera att LLM:er blandar ihop information, ger felaktiga svar och har begränsade kontextfönster. Målet är att hämta exakt rätt information i rätt mängd och avgränsa modellerna för att minimera misstag. Detta är svårare än vad man kan tro.
Digital information är ofta fragmenterad. Människor navigerar skickligt detta organiserade kaos och hittar relevant information med hjälp av kunskap, instinkt och erfarenhet. Automatiserade system saknar dessa förmågor och behöver därför standardiserade metoder som fungerar i alla situationer, oavsett svårighetsgrad.
Bara för att information finns betyder det inte att den är relevant. Förmågan att identifiera och filtrera bort irrelevant information är en kritisk mänsklig färdighet som är mycket svår för både automatiserade system och språkmodeller.
För människor är kontexten ibland självklar, men för en LLM måste den förklaras tydligt. Antaganden som vi gör automatiskt i samtal fungerar inte alltid på samma sätt för en LLM.
Detta är allt du behöver tänka på när du utvecklar AI-applikationer som konverserar med användare. Dessutom behöver du tänka på gränssnittet och användarupplevelsen (UX) för att leverera en komplett produkt.
Så, vad tror jag händer framåt?
När vi nu utmanar gränserna för vad LLM:er klarar av så skiftar fokus från att bara förbättra modellerna själva till att förbättra vår förmåga att ge dem rätt kontext.
Det är sannolikt därför vi ser fler ramverk och no code-plattformar dyka upp den senaste tiden. Det är nämligen inte språkmodellen i sig som skapar magin, utan snarare orkestreringen av kontext.
Finns det ett tak för hur bra dessa tjänster kan bli? Kanske, men vi är fortfarande i början av vad som är möjligt. De kringliggande systemen och verktygen utvecklas snabbt och öppnar ständigt nya möjligheter.
Med en växande förståelse för hur vi bäst kombinerar mänskliga färdigheter med AI:s styrkor kan vi fortsätta skapa imponerande och värdefulla lösningar som verkligen gör skillnad.
Framtiden är lovande, och potentialen är enorm.